

时间:2024-09-09
深度学习当中,通常模型比较大,参数较多,训练所需要数据的量也很大,得益于GPU加速计算的方式,近几年大放异彩。由于模型参数很多,参数空间很大,如何快速寻找到一个参数空间中相对较好的局部最优点就至关重要,由于模型的非线性和高维度,通过梯度下降的方式去优化一个模型参数成为主流。
首先列出下面比较常见的优化器,然后一一介绍其动机以及细节
批次梯度下降(BGD)对整个数据集计算梯度,然后再向梯度的反方向进行更新模型参数,使得loss减小。
由于计算整个数据集的梯度,需要较大的计算量,所以为了提升效率,采用随机采样的方式来计算梯度,随机梯度下降就是计算单个样本的梯度,然后更新模型参数。减小了计算量,大大提升更新的频率。
随机梯度下降由于是采用一个样本点代替整个数据集,会带来较大的方差,导致模型参数更新过程中的不稳定性。为了减小方差,提升稳定性,采样的方式不是随机取一个样本,而是取一个小批次的样本来代替整个数据集,这样即提升了效率,也兼顾了更新过程中的稳定性。
动量梯度下降是对梯度下降的一个优化,主要为了解决梯度在更新过程中,在某些维度变化比较大,造成来回震荡的现象。而通过增加一个指数加权移动平均值,从而考虑了过去一段时间中梯度是否与当前梯度一致。如果一致,则将沿该方向更新,如果不一致,则会与过去的梯度进行一部分抵消。
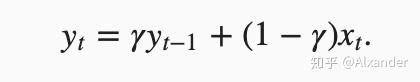
相比与直接梯度下降,动量梯度下降可以收敛得更快,同时学习率可以设置得更大。
超参数momentum的含义:
由于EMA的存在,如果方向一致的情况下(假设g在更新过程中保持不变),动量梯度下降会将梯度最高放大 1/(1-momentum)倍。
之前的梯度下降算法,针对一个模型的参数,其学习率都是一致的。Adaptive gradient算法,最重要的是提出了一个针对不同参数学习率可以动态适应。
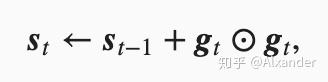

通过计算每个参数梯度的平方和,将每次更新的学习率除每个参数之前累计更新梯度的平方和,来进行自适应更新。对于更新较少的参数,学习率大些,对于频繁更新的参数,学习率小些。
Adagrad算法存在一个问题,随着模型梯度更新迭代,由于需要除累计梯度的平方和,更新的梯度会越来越小。为了解决这个问题, RMSProp算法就是在Adagrad的基础上,在s上做了一个指数加权移动平均。
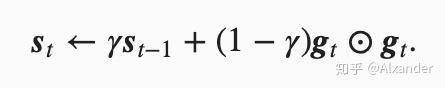

相当于计算s时,取了一个时间窗口,这样避免更新越来越小的情形。
由于梯度的累计平方和,永远为正,所以超参数 同样具有放大s的功能,而放大s具有将学习率调小的效果。
Adadelta算法采用 来代替学习率,这样可以不需要设置学习率。

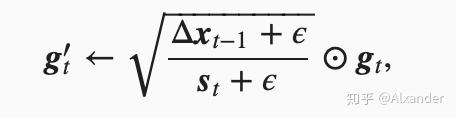


adam是实际场景中最常用的一个优化更新算法之一,比较通常默认设置就可以取得不错的效果。
Adam算法融合了动量梯度下降和RMSProp算法,在梯度上做了指数加权移动平均(EMA),在梯度平方和上也做了EMA。同时,对于初始冷启动阶段进行了修正调节。
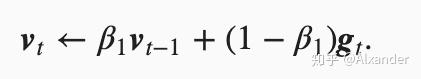

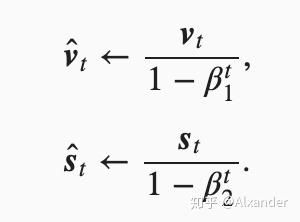
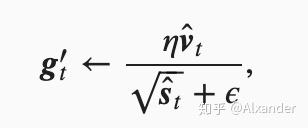

超参数 :
调节过程中,对于对梯度和梯度的平方和进行放大效果,分别是
倍,所以想调大学习率,需要缩小
,增大
,反之相反。
Nesterov动量可以解释为往标准动量方法中添加了校正因子。
由于每次的batch相当于采样,然后对梯度进行估计,深度学习一般要求样本是IID的(独立同分布),这样可以得到一个无偏的采样,但是采样的过程中,方差是一直存在的。这是需要对学习率进行衰减的原因,从而收敛。
2. warmup
由于初始情况下,模型的参数是随机初始化的,并不能保证在一个合适的初始点,所以在刚开始更新参数的时候,偏向于小幅度更新,避免震荡。


 电话:020-88888888 / 13988888888
电话:020-88888888 / 13988888888






 88888888
88888888 13988888888
13988888888 020-88888888
020-88888888